How Does A Computer Calculate Eigenvalues?
The two most practically important problems in computational mathematics are solving systems of linear equations, and computing the eigenvalues and eigenvectors of a matrix. We’ve already discussed a method for solving linear equations in A Deep Dive Into How R Fits a Linear Model, so for this post I thought we should complete the circle with a discussion of methods which compute eigenvalues and eigenvectors.
The reader familiar with a standard linear algebra curriculum may wonder why this question is even interesting, all that must be done is to compute the characteristic equation of the matrix, then compute its roots. While this is the textbook method, it is a poor method for numerical computation, because
- Computing the characteristic equation of a matrix involves symbolically computing a determinant, which is expensive, and should be avoided if possible.
- Computing the roots to a polynomial equation is also a difficult problem. Even though techniques like Newton’s method exist, the sets of initial points that converge to each individual root are extremely complex, so choosing a collection initial points so that all the roots are found is very difficult. In fact, popular methods for polynomial root finding are closely related to the eigenvalue finding algorithms discussed below.
The standard algorithm for computing eigenvalues is called the -algorithm. As the reader can surely guess, this involves the -factorization of the matrix in question (as a quick reminder, the -factorization encodes the Gram–Schmidt process for orthonormalizing a basis).
The details of the -algorithm are mysterious. Suppose we are interested in computing the eigenvalues of a matrix . The first step of the -algorithm is to factor into the product of an orthogonal and an upper triangular matrix (this is the -factorization mentioned above)
The next step is the mystery, we multiply the factors in the reverse order
This is quite a bizarre thing to do. There is no immediate geometric or intuitive interpretation of multiplying the two matrices in reverse order.
The algorithm then iterates this factor-and-reverse process
…and so on. This process eventually leads us (in the limit) to an upper triangular matrix (though it is not at all obvious why this would be the case), and the diagonal entries on this limit are the eigenvalues of .
In this essay we will hopefully de-mystify this process, and give the reader some insight into this important algorithm.
Software
I first learned about the -algorithm when writing this C library, which implements many of the standard numerical linear algebraic algorithms. In this post, I will be providing python code implementing the various algorithms; hopefully this will be more accessible to many readers.
To help with the numerous numpy arrays that needed to be typeset as matrices in latex, I wrote this small python package: np2latex. May it go some way to relieving the reader’s tedium, as it did mine.
Acknowledgements
The impetus to write this material down was a question from my student Michael Campbell.
Greg Fasshauer’s notes here, and here were very helpful, as was the source paper by John Francis: The QR Transformation, I.
Setup
We will restrict ourselves to finding eigenvalues (and eigenvectors) of symmetric matrices , and we will assume that has no repeated eigenvalues, and no zero eigenvalues 1. This is the most useful case in practice (for example, in finding the principal components of a data set ). There are few couple important consequences of this assumption that we will make note of:
- All symmetric matrices (with real number entries) have a full set of eigenvalues and eigenvectors.
- The eigenvalues are all real numbers.
- The eigenvectors corresponding to different eigenvalues are orthogonal (eigenvectors of different eigenvalues are always linearly independent, the symmetry of the matrix buys us orthogonality).
As a running example, we will take the matrix
This matrix was constructed as a product , where
is an orthogonal matrix, and
This immediately implies that is symmetric (which could also be verified by inspection), and that it has eigenvalues , and . The associated eigenvectors are the columns of 2.
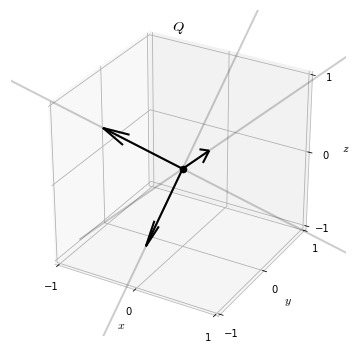
We will often have need to visualize a matrix, especially orthogonal matrices. To do so we will draw the columns of the matrix as vectors in . For example, in this way we can visualize the matrix as
Power Iteration
The basic idea underlying eigenvalue finding algorithms is called power iteration, and it is a simple one.
Start with any vector , and continually multiply by
Suppose, for the moment, that this process converges to some vector (it almost certainly does not, but we will fix that in soon). Call the limit vector . Then must satisfy 3
So is an eigenvector of with associated eigenvalue .
We see now why this process cannot always converge: must possess an eigenvalue of . To fix things up, let’s normalize the product vector after each stage of the algorithm
With this simple addition, it’s not difficult to show that the process always converges to some vector. Now, instead of the limit vector staying invariant under multiplication by , it must stay invariant under multiplication by followed by normalization. I.e., must be proportional to .
So the convergent vector is an eigenvector of , this time with an unknown eigenvalue.
def power_iteration(A, tol=0.0001):
v = np.random.normal(size=A.shape[1])
v = v / np.linalg.norm(v)
previous = np.empty(shape=A.shape[1])
while True:
previous[:] = v
v = A @ v
v = v / np.linalg.norm(v)
if np.allclose(v, previous, atol=tol):
break
return vApplying power iteration to our example matrix , we can watch the iteration vector converge on an eigenvector
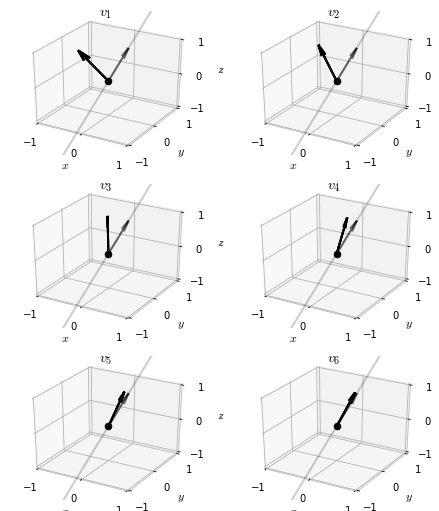
The eigenvector is
The eigenvalue corresponding to this eigenvector , which happens to be the largest eigenvalue of the matrix . This is generally true: for almost all initial vectors , power iteration converges to the eigenvector corresponding to the largest eigenvalue of the matrix 4.
Unfortunately, this puts us in a difficult spot if we hope to use power iteration to find all the eigenvectors of a matrix, as it almost always returns to us the same eigenvector. Even if we apply the process to an entire orthonormal basis, each basis element will almost surely converge to an eigenvector with the largest eigenvalue.
Luckily, there is a simple way to characterize the starting vectors that are exceptional, i.e. the ones that do not converge to the largest eigenvector.
Convergence with an Orthogonal Vector
Recall from our earlier setup that the eigenvectors of a symmetric matrix are always orthogonal to one another. This means that if we take any vector that is orthogonal to the largest eigenvector of , then will still be orthogonal to .
So, if we start the iteration at , the sequence generated from power generation cannot converge to , as it stays orthogonal to it throughout all steps in the process.
The same arguments as before (but applied to the restriction of to the orthogonal complement to ) imply that this orthogonal power iteration must converge to something, and that this something must be another eigenvector! In this case, we almost always end up at the second largest eigenvector of .
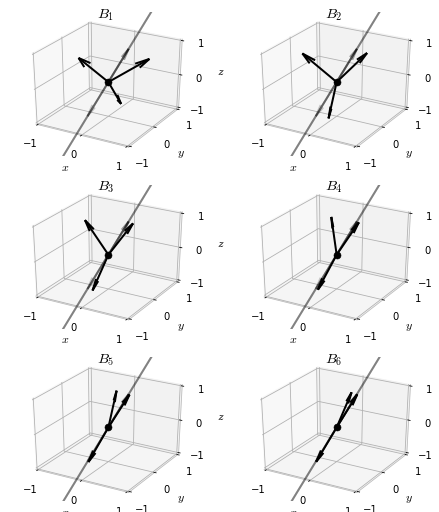
It’s now obvious that we can continue this process of restricting focus to a smaller orthogonal subspace of the eigenvectors we have already found, and applying power iteration to compute the next eigenvector. In this way, we will eventually find the entire sequence of eigenvectors of : .
So, in principle, the problem is solved! Yet, this is not how this is usually done in practice, there are still some interesting refinements to the basic algorithm we should discuss.
Simultaneous Orthogonalization
In our previous discussion of power iteration, we needed to restart the algorithm after each eigenvector is found. If we want a full set of eigenvectors of the matrix, we need to run a full power iteration sequence (the dimension of the matrix ) times.
The reason we could not simply run power iterations simultaneously, seeded with a basis of vectors , is that we were more or less guaranteed that all of them would converge to the same vector (the with the largest eigenvalue). If we want to find all the eigenvectors at once, we need to prevent this from happening.
Suppose that we adjust the basis at each iteration by orthogonalizing it. I.e., at each step we insert the operation
If we are lucky, this will prevent all the separate power iterations from converging to the same place. Instead they will (hopefully) converge to an orthogonal basis. This is indeed the case, and the resulting algorithm is called simultaneous orthogonalization.
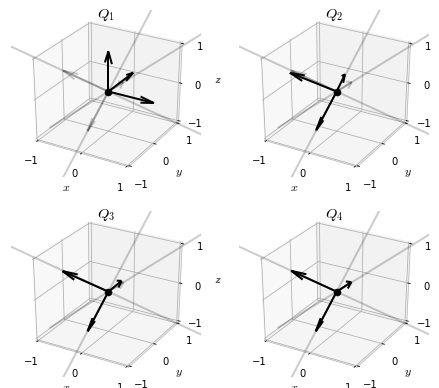
Recall that the process of orthogonalizing a basis is encoded in the -factorization of a matrix. With this in mind, we can write out the steps of the simultaneous orthogonalization algorithm as follows.
Start with . Then proceed as follows
…and so on. The sequence of orthogonal matrices thus generated converge, and the limit is a matrix of eigenvectors of .
In code
def simultaneous_orthogonalization(A, tol=0.0001):
Q, R = np.linalg.qr(A)
previous = np.empty(shape=Q.shape)
for i in range(100):
previous[:] = Q
X = A @ Q
Q, R = np.linalg.qr(X)
if np.allclose(Q, previous, atol=tol):
break
return QIf we apply this algorithm to our example matrix , the sequence of matricies generated is
We see that, at least up to sign, the simultaneous orthogonalization algorithm reproduces the matrix of eigenvectors of , as intended.
A Mathematical Property of Simultaneous Orthogonalization
We will need an interesting property of the iterates of the simultaneous orthogonalization algorithm for later use, so let’s digress for the moment to discuss it.
The steps of the simultaneous orthogonalization algorithm can be rearranged to isolate the upper triangular matricies
If we multiply the resulting sequences together, we get, for example
Using the orthogonality of the ’s results in
It’s easy to see that this applies to any stage of the computation; so we get the identities
or, restated
Now, since we assumed that has no zero-eigenvalues, it is invertible. The -factorizations of invertible matrices are unique 5. This means that we can interpret the above identity as expressing the unique -factorization of the powers of
QR Algorithm
While the simultaneous orthogonalization technically solves our problem, it does not lend itself easily to the type of tweaks that push numerical algorithms to production quality. In practice, it is the -algorithm mentioned in the introduction that is the starting point for the eigenvalue algorithms that underlie much practical computing.
As a reminder, the -algorithm proceeded with a strange reverse-then-multiply-then-factor procedure
This procedure converges to a diagonal matrix 6, and the diagonal entries are the eigenvalues of .
We’re in a confusing notational situation, as we now have two different algorithms involving a sequence of orthogonal and upper-triangular matrices. To distinguish, we will decorate the sequence arising from the -algorithm with tildes
In code
def qr_algorithm(A, tol=0.0001):
Q, R = np.linalg.qr(A)
previous = np.empty(shape=Q.shape)
for i in range(500):
previous[:] = Q
X = R @ Q
Q, R = np.linalg.qr(X)
if np.allclose(X, np.triu(X), atol=tol):
break
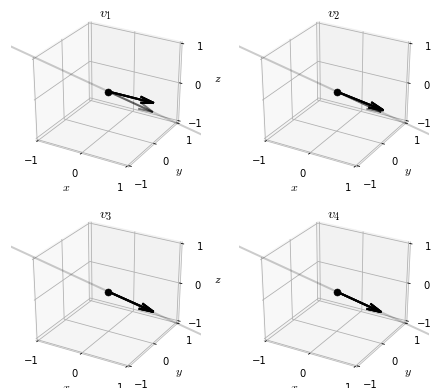
return QVisualizing the iterates of the -algorithm reveals an interesting pattern.
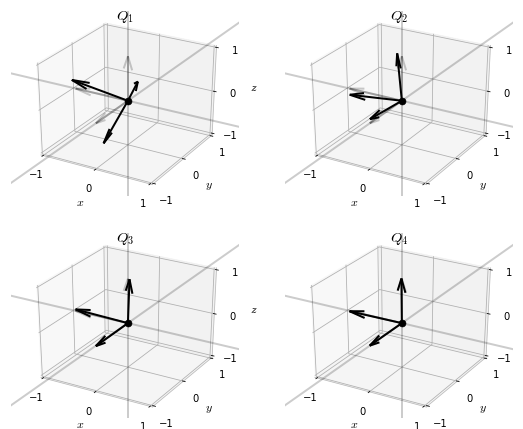
While the iterates of the simultaneous orthogonalization algorithm converged to a basis of eigenvectors of , the iterates of the -algorithm seem to converge to the identity matrix 7.
This suggests that the iterations may be communicating adjustments to something, and that the product
may be important.
Let’s see if we can get a hint of what is going on by computing these products
This is the best possible situation! The products of the matricies converge to the basis of eigenvectors.
This is great, but it is still very mysterious exactly what is going on here. To illuminate this a bit, we now turn to uncovering the relationship between the simultaneous orthogonalization algorithm and the -algorithm.
The Connection Between the QR and Simultaneous Orthogonalization Algorithms
Recall our identity relating the iterates of the simultaneous orthogonalization to the powers of
Let’s seek a similar relation for the algorithm. If we succeed, we can leverage the uniqueness of the -factorization to draw a relationship between the two algorithms.
The algorithm begins by factoring
This means that, for example
Now, each product are exactly those matrices that are factored in the second iteration of the algorithm, so
We can apply this trick one more time, is exactly the matrix factored in the third iteration of the algorithm, so
So, we have two competeing factorizations of into an orthogonal matrix and an upper triangular matrix
Given that -factorizations of invertible matricies are unique, we conclude the relations
and
This explains our observation from before: we already know that , so we immediately can conclude that as well.
The Products RQ
We have one final point to wrap up: we earlier stated that the products in the algorithm converge to a diagonal matrix, and the diagonal entries are the eigenvalues of , why is this so?
Let’s first demonstrate that this is the case in our running example.
To begin to understand why this is the case, let’s start from the fact that, for sufficiently large , the product matrix is a matrix of eigenvectors. Letting denote the diagonal matrix of associated eigenvalues, this means that 8
Shuffling things around a bit
But , so
So, alltogether
Which explains the convergence of the products.
Conclusions
The -algorithm presented in this post is not yet production ready, there are various tricks that can be employed to make it more numerically stable, and converge more quickly. We will leave investigating these ideas more to the user.
Eigenvalues and eigenvectors of matrices are undoubtedly one of the most important mathematical concepts ever discovered. They occur again and again in analysis, topology, geometry, statistics, physics, and probably any subject which uses mathematics in any non-trivial way. It is nice to know at least a little about how they can practically be computed, if only to pay respect to their incredible utility.
-
The case of zero eigenvalues is not difficult to treat, as we can simply resrict the action of to the orthogonal complement of the null space, where it has all non-zero eigenvalues. The case of repreated eigenvalues is more difficult, and we will leave it to the reader to stydy further if interested. ↩
-
This is easy to see by inspection: . ↩
-
By taking limits of the equation . ↩
-
Largest in the sense of absolute value. ↩
-
For a proof, see the paper of Francis. ↩
-
In the general case where eigenvalues may be repeated, these matricies converge to an upper triangular matrix, the Schur form of A. The eigenvalues are on the diagonal of this limit matrix. ↩
-
Actually, not exactly an identity matrix. More preciesely, a square diagonal matrix with with a or for each entry. ↩
-
: Of course, this is really an approximate equality which becomes exact it the limit of . ↩